Table of Contents
TBB (Intel)
Intel Threading Building Blocks (also known as TBB (Intel)) is library developed by Intel Corporation for writing software programs that take advantage of multi-core processors. The library consists of data structures and algorithms that allow a programmer to avoid some complications arising from the use of native threading packages such as POSIX threads, Windows ® threads, or the portable Boost Threads in which individual threads of execution are created, synchronized, and terminated manually.
BOLT supports parallelization using Intel Threading Building Blocks (TBB (Intel)). You can switch between CL/AMP and TBB (Intel) calls by changing the control structure.
Setting up TBB (Intel) with Bolt.
To start using high performance MultiCore routines with Bolt. Install TBB (Intel) from here On Windows ®, add TBB_ROOT to your environment variable list. e.g. TBB_ROOT=<path-to-tbb-root>. Run the batch file tbbvars.bat (e.g. tbbvars.bat intel64 vs2012) which is in TBB_ROOT%\bin\directory. This batch file takes 2 arguments. <arch> = [32|64] and <vs> - version of Visual Studio. If you want to set it globally then append the TBB (Intel) dll path e.g. TBB_ROOT% \intel64\vc11 in “PATH” Environment variable. This will set all the paths required for TBB (Intel).
NOTE: On Linux ®, set the TBB_ROOT , PATH and LD_LIBRARY_PATH variables.
E.g. 'export TBB_ROOT=<path-to-tbb-root>'
'export LD_LIBRARY_PATH = <path-to-tbb-root>/lib/intel64/gcc-4.4:$LD_LIBRARY_PATH'
'export PATH = <path-to-tbb-root>/include:$PATH'
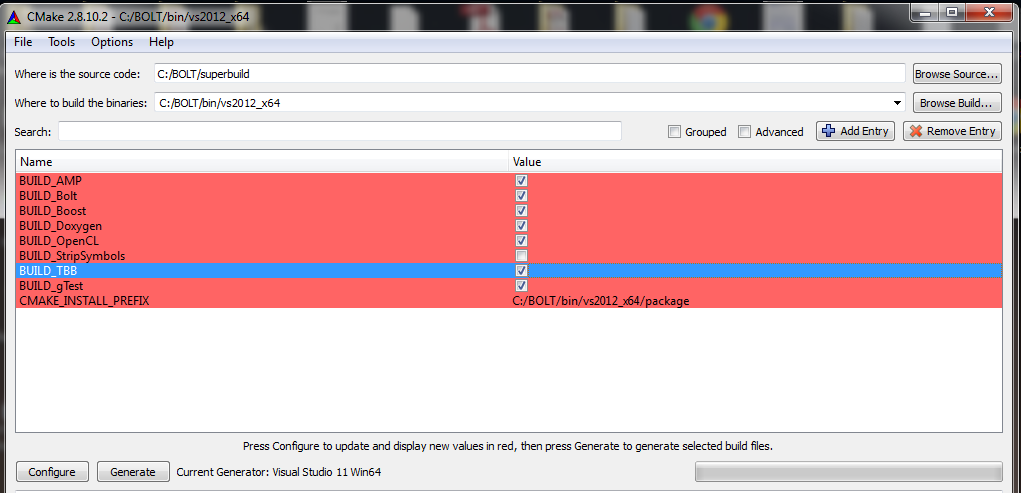
Then install CMake (see Using CMake build infrastructure). To enable TBB (Intel), BUILD_TBB check box should be checked in CMake configuration list as shown below, the build procedure is as usual.
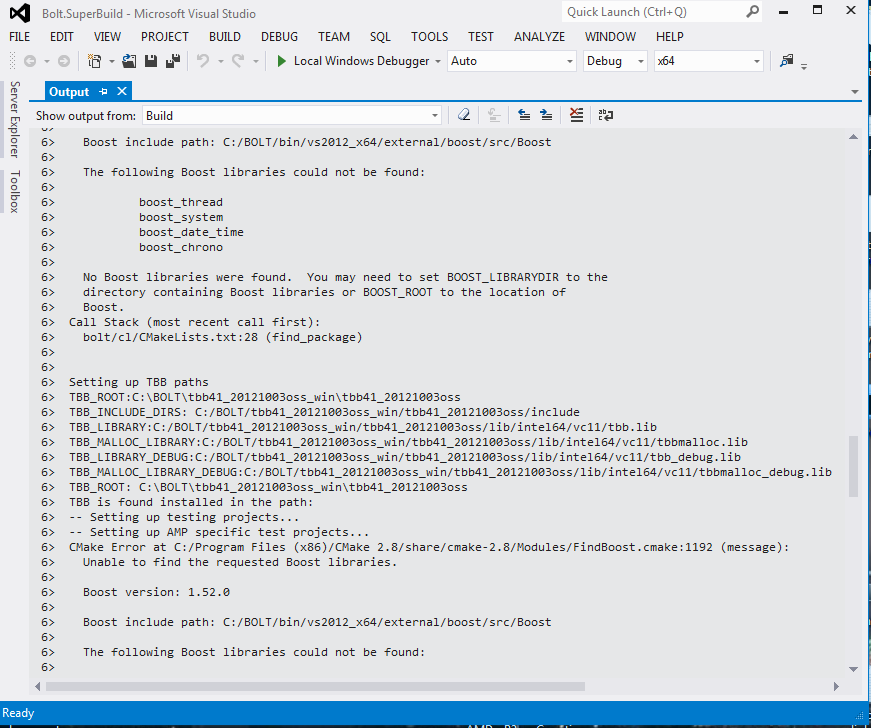
On successful build, the TBB (Intel) paths are shown in the Visual Studio Output tab as shown below.
TBB (Intel) routines in Bolt
These are the Bolt routines with TBB (Intel) support for MultiCore path enlisted along with the backend:
- Copy - OpenCL
- Copy_n - OpenCL
- Count - OpenCL/AMP
- Count_if - OpenCL/AMP
- Exclusive_Scan - OpenCL/AMP
- Exclusive_Scan_by_key - OpenCL
- Fill - OpenCL
- Fill_n - OpenCL
- Generate - OpenCL
- Generate_n - OpenCL
- Inclusive_Scan - OpenCL/AMP
- Inclusive_Scan_by_key - OpenCL
- Inner_Product - OpenCL
- Max_Element - OpenCL
- Min_Element - OpenCL
- Reduce - OpenCL/AMP
- Reduce_By_Key - OpenCL
- Sort - OpenCL/AMP
- Sort_By_Key - OpenCL
- Stable_Sort - OpenCL/AMP
- StableSort_By_Key - OpenCL
- Transform - OpenCL/AMP
- Transform_Exclusive_Scan - OpenCL
- Transform_Inclusive_Scan - OpenCL
- Transform_Reduce - OpenCL/AMP
- Binary_Search - OpenCL
- Merge - OpenCL
- Scatter - OpenCL
- Scatter_if - OpenCL
- Gather - OpenCL
- Gather_if - OpenCL
Running TBB (Intel) routines in Bolt
Control object
Bolt function can be forced to run on the specified device. Default is "Automatic" in which case the Bolt runtime selects the device. Forcing the mode to MulticoreCpu will run the function on all cores detected. There are two ways in BOLT to force the control to MulticoreCPU.
- Setting control to MulticoreCPU Globally: This will set the control to MultiCore CPU globally, So reference to any BOLT function will always run MultiCore CPU path.bolt::cl::control& myControl = bolt::cl::control::getDefault( );myControl.waitMode( bolt::cl::control::NiceWait );myControl.setForceRunMode( bolt::cl::control::MultiCoreCpu );
- Setting control to MuticoreCPU locally This will set the control to MultiCore CPU locally, passing this control object as first parameter to BOLT function enables multicore path only for the calling function.bolt::cl::control myControl = bolt::cl::control::getDefault( );myControl.setForceRunMode(bolt::cl::control::MultiCoreCpu);
AMP has same use case only CL namespace(bolt::cl) needs to be change to AMP(bolt::amp)
Other Scenarios:
- Using MulticoreCPU flag with BOLT function, when TBB (Intel) is not installed on the machine will throw an exception like "The MultiCoreCpu version of <function> is not enabled to be built." Proper care has to be taken to make sure that TBB (Intel) is installed in the system.
- The default mode is "Automatic" which means it will go into OpenCL ™ path first, then TBB (Intel), then SerialCpu. The examples discussed below in the next subsection focus on how TBB (Intel) parallelization is achieved with different functions.
Example:
Transform Reduce:
Transform_reduce performs a transformation defined by unary_op into a temporary sequence and then performs reduce on the transformed sequence.
AMP backend variant:
Inclusive and Exclusive Scan By key:
Inclusive_scan_by_key performs, on a sequence, an inclusive scan of each sub-sequence as defined by equivalent keys.
AMP backend variant:
Sort:
Sort the input array based on the comparison function provided.
AMP backend variant:
